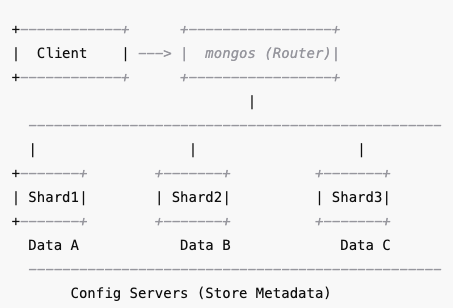
Sharding in MongoDB is a horizontal scaling technique that distributes large datasets across multiple servers (shards). It helps improve performance, availability, and scalability when a single machine can’t handle high read/write loads.
1. Why Use Sharding?
Without sharding, a single MongoDB server might face:
- High memory usage (handling large datasets).
- Slow queries (due to increased data scanning).
- Write bottlenecks (as all writes go to one server).
- Limited storage capacity (one machine may not be enough).
Sharding helps by spreading data across multiple servers, making queries and writes faster.
2. Components of MongoDB Sharding
1. Shard (Data Nodes)
- A shard is a MongoDB server (or replica set) that stores a portion of the data.
- Each shard contains a subset of documents based on a predefined shard key.
2. Config Servers
- Config servers store metadata about the cluster (which shard has what data).
- They ensure correct data routing across shards.
3. Query Router (mongos)
- The
mongosacts as a load balancer and query router. - It directs client requests to the correct shard based on the shard key.
Diagram Representation:

3. How Sharding Works?
Step 1: Choose a Shard Key
A shard key is a field in the document that determines how data is distributed across shards.
Example: If we choose userId as the shard key, MongoDB will distribute users based on their IDs.
Step 2: Data Distribution (Shard Ranges or Hashing)
MongoDB uses two ways to distribute data across shards:
1. Range-based Sharding
- Documents are stored in a range based on the shard key.
- Example: If
ageis the shard key, data might be split as:Shard 1 → Users age 1-30 Shard 2 → Users age 31-60 Shard 3 → Users age 61-100 - Best for: Queries filtering on shard key (e.g.,
age > 50).
2. Hashed Sharding
- MongoDB hashes the shard key, distributing data evenly.
- Prevents data hotspots (where one shard gets more queries than others).
- Best for: Random distribution, avoiding uneven data loads.
4. How to Set Up Sharding?
Step 1: Enable Sharding on the Database
sh.enableSharding("myDatabase")
Step 2: Shard a Collection (Choose Shard Key)
sh.shardCollection("myDatabase.users", { "userId": "hashed" })
This will distribute users collection data based on userId across shards.
5. Query Execution in a Sharded Cluster
MongoDB routes queries using mongos:
- Targeted Query (Efficient) → If the query filters on the shard key,
mongossends it to a specific shard. - Broadcast Query (Slow) → If no shard key is used, the query is sent to all shards (expensive).
Example:
db.users.find({ userId: 1001 }) // Query sent to one shard (fast)
db.users.find({ age: 25 }) // Query sent to all shards (slow)
6. Advantages of Sharding
- Improves Read & Write Performance → Distributes load across multiple machines.
- Scalability → More shards can be added as data grows.
- Fault Tolerance → If one shard fails, others still work (with replication).
7. Challenges & Best Practices
- Choosing the Right Shard Key → A bad shard key can lead to imbalanced shards.
- Avoid Broadcast Queries → Always include the shard key in queries.
- Replication Still Needed → Each shard should still be a replica set for fault tolerance.
Summary:
MongoDB sharding is a powerful feature that horizontally scales databases by distributing data across multiple servers.
It improves performance, availability, and scalability, making it ideal for big data applications.